
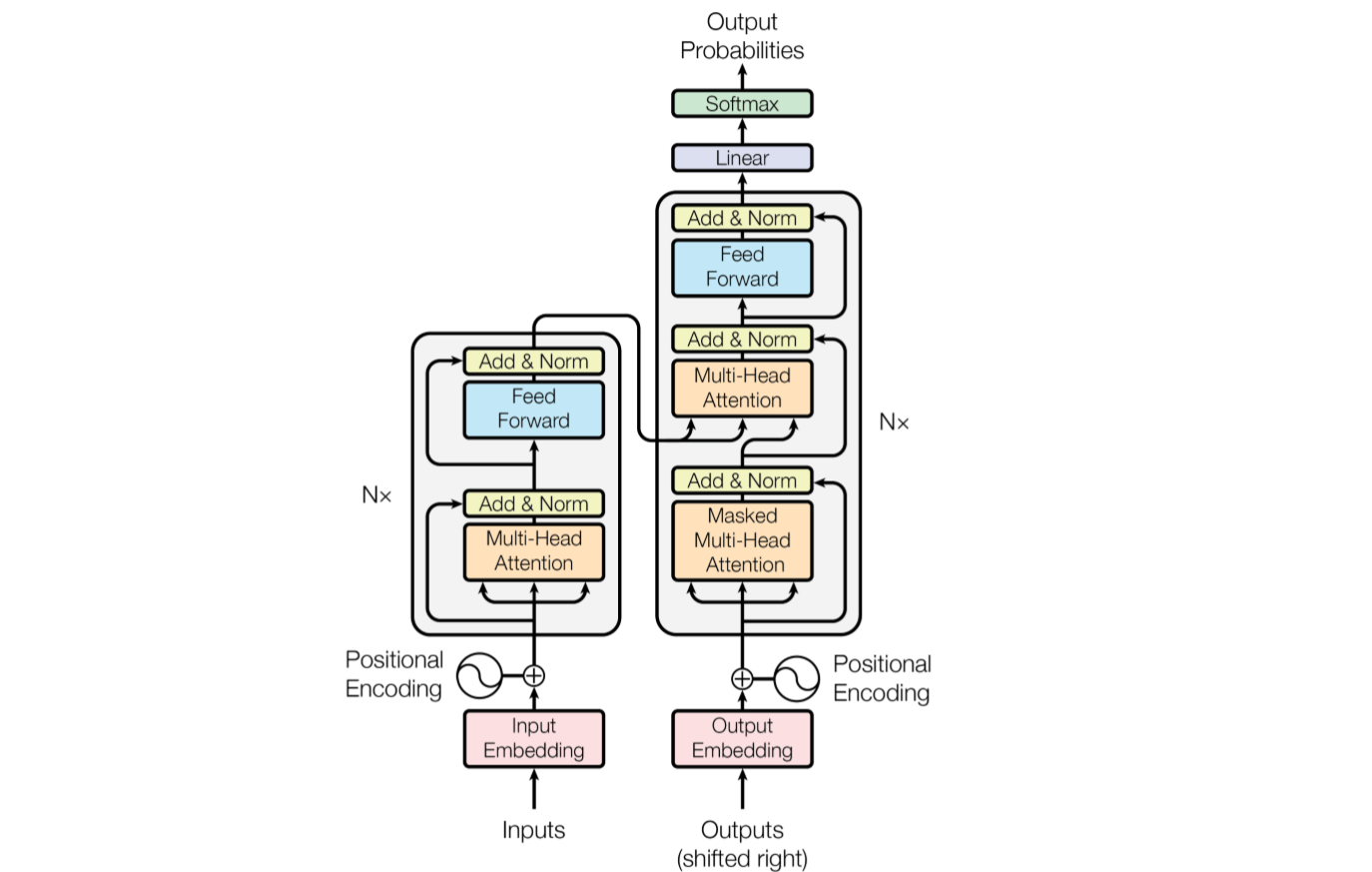
Transformer架構是一種基於自注意力機制(Self-Attention)的深度學習模型,最早由Google團隊在2017年提出,徹底改變了自然語言處理(NLP)領域。其核心是編碼器-解碼器(Encoder-Decoder)架構,用於處理序列資料,特別適合機器翻譯、文本生成等任務。
Transformer架構核心要素
-
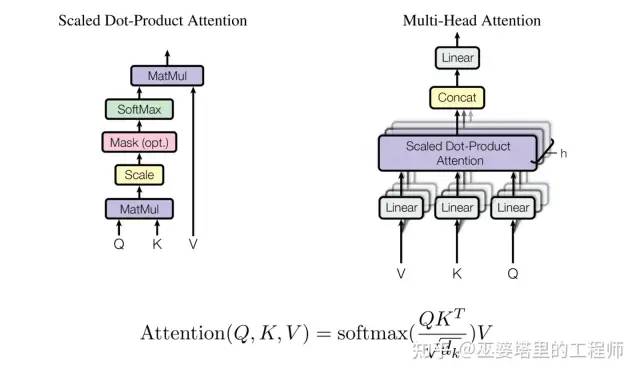
編碼器(Encoder):將輸入序列轉換成豐富的特徵表示。每層包含多頭自注意力機制(Multi-Head Self-Attention)和前饋神經網絡(Feed-Forward Neural Network),並輔以殘差連接和層歸一化,能有效捕捉序列中各部分的關聯。
-
解碼器(Decoder):根據編碼器輸出生成目標序列。解碼器層除了包含多頭自注意力和前饋網絡外,還有一層專門用於關注編碼器輸出的注意力層,確保生成內容與輸入上下文相關。
-
自注意力機制:Transformer的核心創新,允許模型在處理序列時同時關注所有位置的資訊,捕捉長距離依賴,並支持並行計算,顯著提升效率和效果。
-
位置編碼(Positional Encoding):由於Transformer不使用循環或卷積結構,位置編碼用於注入序列中詞語的位置信息,幫助模型理解詞序。
Transformer在Google AI的應用奧秘
Google AI利用Transformer架構推動多項深度學習技術的突破,尤其在自然語言處理領域:
-
語言模型與機器翻譯:Google的BERT、T5等大型語言模型均基於Transformer架構,能理解和生成自然語言,提升搜尋引擎、語音助理的語言理解能力。
-
多模態學習與生成模型:Transformer架構的靈活性使其能擴展至圖像、語音等多種數據類型,支援跨模態任務,推動AI在多領域的應用。
-
高效訓練與推理:Transformer的並行計算特性,結合Google強大的計算資源,實現大規模模型的訓練與部署,促進AI技術的快速迭代和商業化。
所以,Transformer架構憑藉其創新的自注意力機制和編碼器-解碼器設計,成為Google AI推動深度學習革命的基石,廣泛應用於自然語言處理及其他智能任務中,展現出強大的表達能力和靈活性。














WebSeoHK 為香港、澳門和內地提供業界最優質的網站流量服務。我們為客戶提供多種流量服務,包括網站流量、桌面流量、行動流量、Google流量、搜索流量,電商流量、YouTube流量、TikTok流量。我們的網站擁有 100% 的客戶滿意度,因此您可以放心地在線購買大量 SEO 流量。每月僅需 90 港幣即可立即增加網站流量、提高 SEO 效能並增加銷售額!
您在選擇流量套餐時遇到困難嗎?聯繫我們,我們的工作人員將協助您。
免費諮詢