
Crawl-delay 是一個非官方的 robots.txt 指令,用來控制搜尋引擎爬蟲對網站的爬取速度,透過設定兩次爬取之間的秒數延遲,避免伺服器過載。這對大型網站特別有用,可以減少伺服器負擔,維持網站性能和用戶體驗。不過,若設定延遲過長,可能會限制爬蟲在一次訪問中爬取的頁面數量,導致部分頁面無法被索引,影響網站的搜尋能見度。
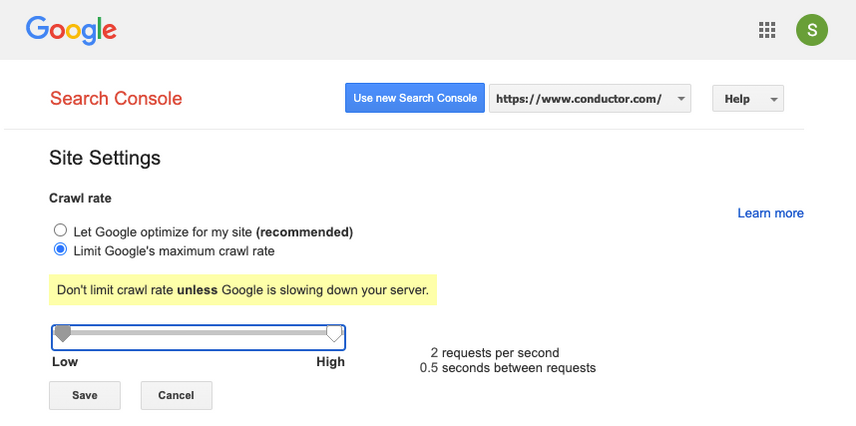
Googlebot 不支援 robots.txt 中的 crawl-delay 指令,Google 建議透過 Google Search Console(GSC)中的「爬取速率」設定來調整爬取頻率。而 Bing、Yahoo、Yandex 等搜尋引擎則支援 crawl-delay 指令,且用法略有不同。
Noindex 則是用來告訴搜尋引擎不要將特定頁面納入索引的指令,通常透過 meta 標籤或 HTTP header 實現。使用 noindex 可以有效避免不想曝光的頁面出現在搜尋結果中,間接釋放爬取預算(crawl budget),讓搜尋引擎更專注於重要頁面。但要注意,Google 仍會爬取帶有 noindex 的頁面,只是不會將其納入索引,因此 noindex 不會直接節省爬取預算,而是透過減少索引頁面數量間接影響。
robots.txt 中的 noindex 指令目前並非 Google 官方正式支援,雖然有實驗證明其有效,但不建議長期依賴,應搭配其他索引控制方法使用。
進階應用建議
-
結合 crawl-delay 與 noindex:
- 使用 crawl-delay 控制爬取速度,避免伺服器過載,尤其是大型網站。
- 使用 noindex 控制不希望被索引的頁面,避免這些頁面佔用索引空間,間接優化爬取預算。
- 由於 Google 不支援 robots.txt crawl-delay,應透過 GSC 調整爬取速率。
- robots.txt noindex 可作為短期輔助工具,但不應取代 meta noindex 或 HTTP header noindex。
-
注意事項:
- 設定 crawl-delay 時需平衡爬取速度與索引完整性,避免過度延遲導致重要頁面未被爬取。
- 不要用 robots.txt disallow 阻止爬取同時希望頁面不被索引,因為 disallow 會阻止爬取,搜尋引擎無法看到 noindex 指令。
- 持續監控 Google Search Console 的爬取狀況和索引狀態,調整策略。
這樣的組合策略能有效管理網站的爬取頻率與索引狀態,兼顧伺服器負載與 SEO 表現。















WebSeoHK 為香港、澳門和內地提供業界最優質的網站流量服務。我們為客戶提供多種流量服務,包括網站流量、桌面流量、行動流量、Google流量、搜索流量,電商流量、YouTube流量、TikTok流量。我們的網站擁有 100% 的客戶滿意度,因此您可以放心地在線購買大量 SEO 流量。每月僅需 90 港幣即可立即增加網站流量、提高 SEO 效能並增加銷售額!
您在選擇流量套餐時遇到困難嗎?聯繫我們,我們的工作人員將協助您。
免費諮詢