
常見的 robots.txt 範例與設計模型 主要依據網站需求,分為以下幾種典型情境:
| 範例類型 | 說明 | 範例內容 |
|---|---|---|
| 1. 所有搜尋引擎可爬取所有頁面 | 無任何限制,適合公開網站 | ``` |
| User-agent: * | ||
| Disallow: | ||
| ``` | ||
| 2. 所有搜尋引擎禁止爬取所有頁面 | 適用於測試或內部網站,正式網站不建議使用 | ``` |
| User-agent: * | ||
| Disallow: / | ||
| ``` | ||
| 3. 特定搜尋引擎可爬取所有頁面 | 例如只允許 Googlebot 爬取 | ``` |
| User-agent: Googlebot | ||
| Disallow: | ||
| ``` | ||
| 4. 特定搜尋引擎禁止爬取所有頁面 | 限制特定爬蟲,其他爬蟲可正常爬取 | ``` |
| User-agent: BadBot | ||
| Disallow: / | ||
| ``` | ||
| 5. 禁止爬取特定目錄或檔案類型 | 控制敏感資料或不希望被索引的內容 | ``` |
| User-agent: * | ||
| Disallow: /cgi-bin/ | ||
| Disallow: /members/data/ | ||
| Disallow: /*.pdf$ | ||
| ``` |
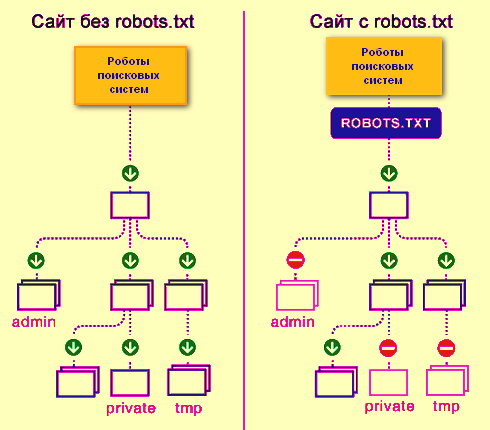
設計模型與應用說明
- 根目錄放置:robots.txt 必須放在網站根目錄(例如 https://www.example.com/robots.txt),搜尋引擎爬蟲才會讀取。
- User-agent:指定規則適用的爬蟲名稱,
*表示所有爬蟲。 - Disallow:禁止爬取的路徑,
/表示整個網站禁止。 - Allow:允許爬取的路徑(Google 支援此指令)。
- 註解:以
#開頭,方便管理者標註說明。 - 檔案類型限制:可用正則符號
$限定特定副檔名禁止爬取,如 PDF 檔案。
不同網站需求範例
- 公開內容網站:通常採用「所有爬蟲可爬取所有頁面」,不設限制,最大化曝光。
- 內部或測試網站:禁止所有爬蟲爬取,避免內容外洩或被索引。
- 新聞網站或大型平台:可能針對 Googlebot 設定優先爬取規則,確保即時內容被快速索引。
- 企業網站:常限制敏感目錄(如會員資料、管理後台)及特定檔案格式,避免被搜尋引擎收錄。
- SEO優化:搭配 meta robots 標籤使用,控制頁面是否被索引或爬取,達到更細緻的搜尋引擎行為管理。
補充建議
- robots.txt 不是安全機制,禁止爬取的內容仍可能被其他方式訪問,敏感資料應另行保護。
- 定期檢查與測試:使用線上工具或瀏覽器直接訪問 robots.txt 檔案,確保設定正確且符合預期。
- 結合 Sitemap:可在 robots.txt 中加入 Sitemap 位置,幫助搜尋引擎更有效率地爬取網站。
以上範例與設計模型可依網站類型與需求靈活調整,達到最佳的搜尋引擎爬取控制效果。















WebSeoHK 為香港、澳門和內地提供業界最優質的網站流量服務。我們為客戶提供多種流量服務,包括網站流量、桌面流量、行動流量、Google流量、搜索流量,電商流量、YouTube流量、TikTok流量。我們的網站擁有 100% 的客戶滿意度,因此您可以放心地在線購買大量 SEO 流量。每月僅需 90 港幣即可立即增加網站流量、提高 SEO 效能並增加銷售額!
您在選擇流量套餐時遇到困難嗎?聯繫我們,我們的工作人員將協助您。
免費諮詢